Assignment #3 - Cats Generator Playground
Part 1: Deep Convolutional GAN
Implement the Discriminator of the DCGAN
Padding: In each of the convolutional layers shown above, we downsample the spatial dimension of the input volume by a factor of 2. Given that we use kernel size K = 4 and stride S = 2, what should the padding be? Write your answer on your website, and show your work (e.g., the formula you used to derive the padding).
From the PyTorch docs,
Thus,
Experiment with DCGANs
| Experiment | Discriminator Loss Curves | Generator Loss Curve |
|---|---|---|
| vanilla | 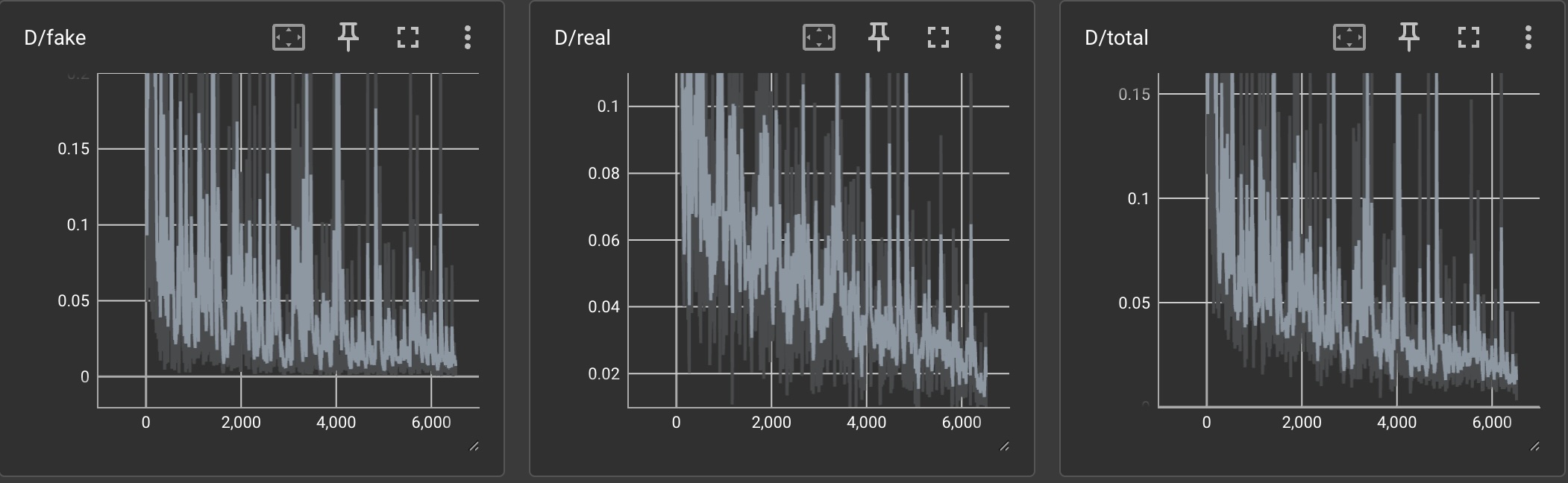 |
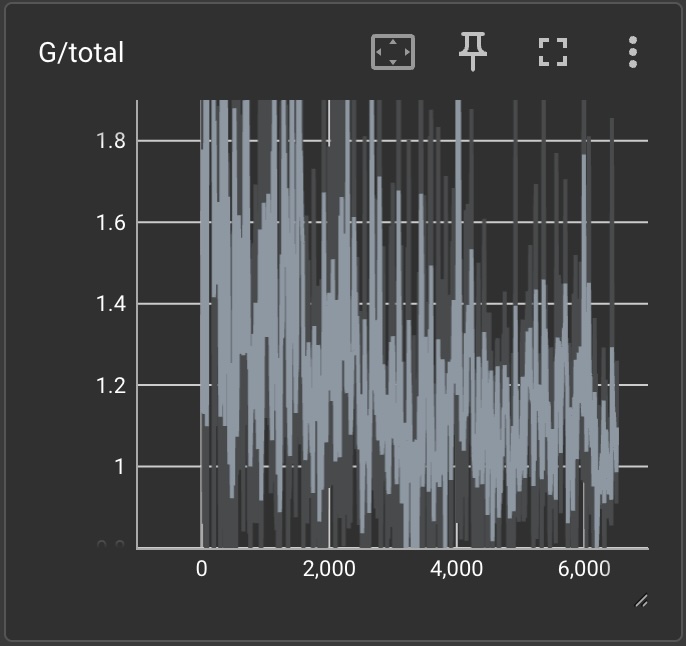 |
| vanilla & diffaug | 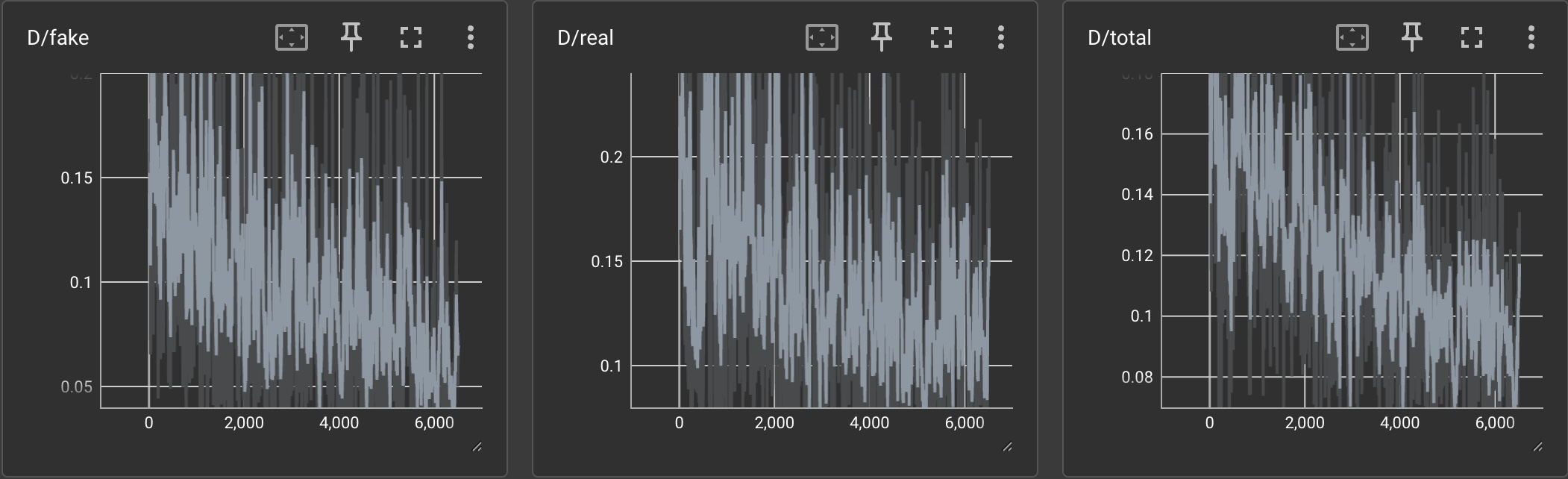 |
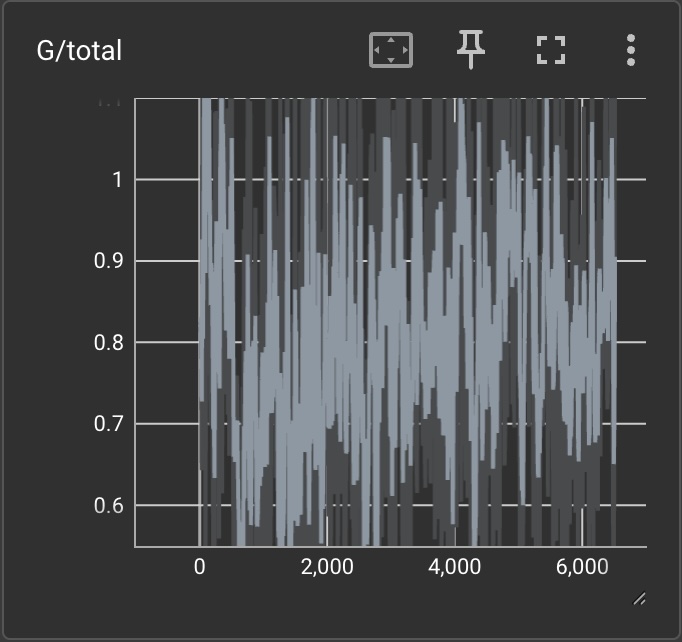 |
Briefly explain what the curves should look like if GAN manages to train.
If a GAN manages to train, the total discriminator loss should be approaching and the total generator loss should be approaching . This is because the discriminator should become better at discerning which photos are real and fake and the generator is trying to make the discriminator uncertain whether a given image is real or fake. The losses should be alternating going up and down because the networks are being adversarially trained. We can see that with more training iterations, the losses decrease. Additionally, we can see that adding differentiable augmentation make the total discriminator loss increase and the total generator loss decrease (which are both good).
| Iteration Number | Generated Sample |
|---|---|
 |
|
 |
Briefly comment on the quality of the samples, and in what way they improve through training.
As we can see, the subject becomes clearer with more training iterations and noticeably more cat-like.
Part 2: Diffusion Model
Diffusion Model Experiments
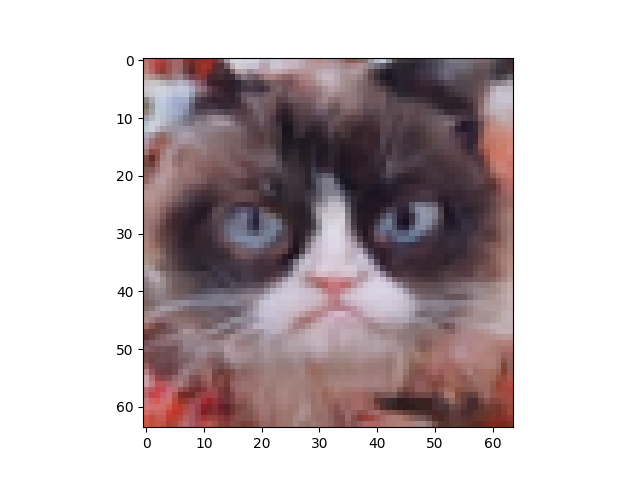
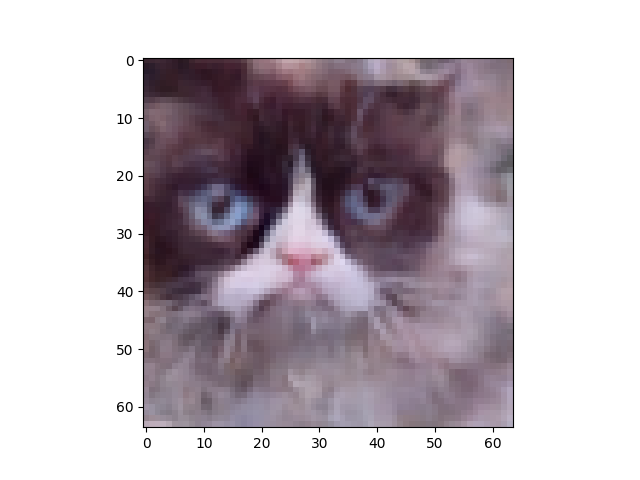
Comparisons with GAN model
- How does the quality of diffusion-generated images compare to GAN-generated images?
The quality of diffusion-generated images seem to be higher than that of GAN-generated images. This is perhaps due to having an easier to optimize objective function as opposed to the adversarial nature of the objective function of the GAN.
- What are the trade-offs in training efficiency and sample diversity?
In comparison to the GAN, the diffusion model took much longer to train. As such, a GAN is much more training efficient than a diffusion model. However, diffusion models seemed to have better sample diversity in comparison to GANs, perhaps because there is more learning signal from denoising versus just trying to fool a discriminator.
- Discuss the strengths and weaknesses of each model in your report.
GANs:
- Strengths:
- More training efficient
- Fast sampling
- Richer latent space
- Weaknesses:
- Training instability
- Less sample diversity
- Lower average quality of samples
- Don’t model likelihood
Diffusion models:
- Strengths:
- More sample diversity
- Higher quality of samples
- Stable training
- Model likelihood
- Weaknesses:
- Less training efficient
- Slow sampling
- Less structured latent space
Part 3: CycleGAN
CycleGAN Experiments
grumpifyCat
No Cycle Consistency Loss
| Iteration Number | ||
|---|---|---|
 |
 |
|
 |
 |
Cycle Consistency Loss
| Iteration Number | ||
|---|---|---|
 |
 |
|
 |
 |
Do you notice a difference between the results with and without the cycle consistency loss? Write down your observations (positive or negative) in your website. Can you explain these results, i.e., why there is or isn’t a difference between the two?
With cycle consistency loss, the original details (such as eyes and mouth) are better preserved. This is probably due to the fact that the generators need to focus on maintaining the original domain’s features since there is an additional MSE loss between the original image and the image generated to a separate domain and then back. However, it seems like the samples without cycle consistency loss look more natural because the generator only needs to worry about fooling the discriminator.
apple2orange
No Cycle Consistency Loss
| Iteration Number | ||
|---|---|---|
 |
 |
|
 |
 |
Cycle Consistency Loss
| Iteration Number | ||
|---|---|---|
 |
 |
|
 |
 |
Do you notice a difference between the results with and without the cycle consistency loss? Write down your observations (positive or negative) in your website. Can you explain these results, i.e., why there is or isn’t a difference between the two?
With cycle consistency loss, the original details (such as lightning, the texture of the fruit) are better preserved. The explanation for this is in grumpifyCat, so not re-explaining.
Bells & Whistles
Generate sample using a pre-trained diffusion model
I generated 2 images based off of the grumpifyCat dataset. Clearly I didn’t do enough prompt engineering to be make the pose of the generated cat the same as that of the source cat.
| Prompt | Source Image | Sampled Image |
|---|---|---|
| Grumpy cat in the same pose |  |
 |
| Russian blue cat in the same pose |  |
 |
Get your CycleGAN to work on a dataset of your choice
I used the summer2winter_yosemite dataset provided in https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
Here are the results after iterations.


Train your GAN to generate higher-resolution images
I trained DCGAN on grumpifyB256 with differentiable augmentation, and this is the result at iterations. Seems to look much better than with lower resolution input images.

Train the CycleGAN with the DCDiscriminator for comparison
| Discriminator | ||
|---|---|---|
DCDiscriminator |
 |
 |
PatchDiscriminator |
|
|
It seems that in the case, the DCDiscriminator's samples are very blurry and don’t distinctly show the Russian Blue. With the PatchDiscriminator, the generated Russian Blues are much more distinct from the background. This make sense because with a patch discriminator, the generator has to make every patch more realistic to fool the discriminator. When the discriminator is only determining if the entire image is real or fake, that let’s the generator be “lazier” in a sense because not every patch has to be realistic.